Reflections on Hello’s tech stack.
Writing this before I forget some the details of the technology choices we made at Hello.
Context: Building a IoT device with a very small team targeting, a ambitious deadline of 11 months from idea to shipping out of the factory.
⚠️ It’s important to note that the technology choices we made were for the most part, conscious decisions aligned with a set of values the engineering team shared. If you and your team share similar values, you might find some of the choices we made valuable. If you do not, they might not make sense. To each her own.
I am also not entirely oblivious to the fact that the company recently went bust. I deeply believe that it went bust despite a solid engineering & design team. There is little doubt that I am biased. As usual, apply skepticism where appropriate.
With that out of the way:
- Architecture Overview
- What worked well
- What worked okay
- What we probably should have done differently
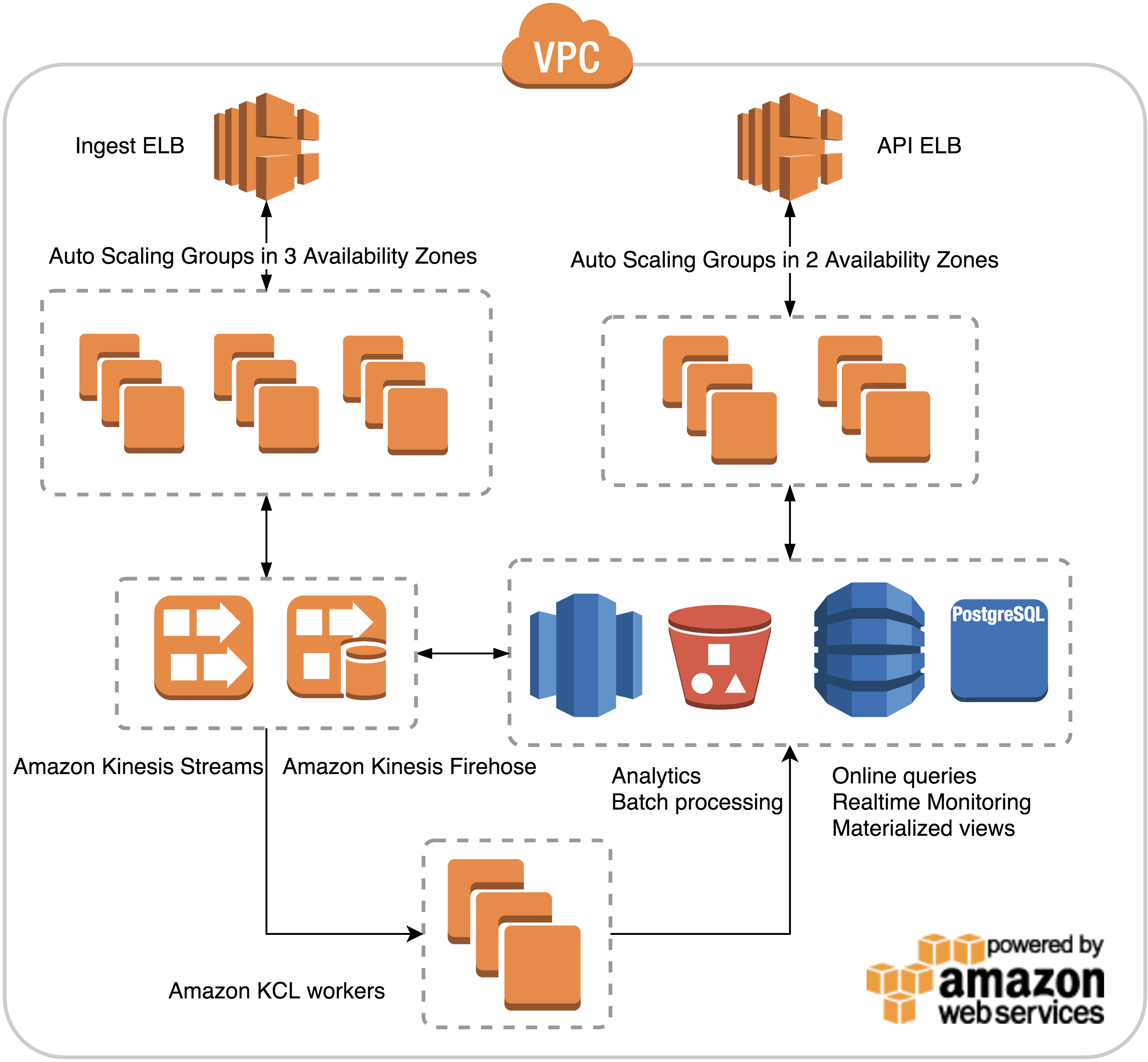
Architecture Overview
What worked well
HTTP as protocol for device <-> server communication.
While some might argue that using HTTP adds a significant amount of overhead, the ubiquity of the protocol and the ease of use in many different programming languages/tools made it an ideal choice for building reliable ingestion pipeline.
TLS + HMAC for security and payload integrity
TLS 1.2 + HMAC-SHA1.
Protocol Buffers
Protobufs used as a serialization protocol for device <-> server, device <-> device and device <-> phone communications. Pretty much everywhere :) Auto-generated serializers/deserializers for many different programming languages (c, java, go, python). Compact on the wire, obvious documentation of new or deprecated attributes. A little verbose with nested messages.
Dropwizard
Dropwizard for the HTTP server. Production grade applications out of the box, no frills, no BS, good performance, great tooling, sensible defaults. Probably the most impactful choice we made. Thanks @coda.
Java + Guava
Despite being a verbose language, the benefits of the type system + good hygiene around limited mutability yielded solid results with few bugs, high confidence that things worked. We probably abused Optional<T> and made some parts of our codebase more verbose than they really had to be. But with a total of a handful of NPEs over 3 years of processing ~100m req/day, difficult to argue with its effectiveness. Building uber-jars, aka OG containers, for a single binary deploy process was fantastic. Would not have chosen Java if it weren’t for Guava.
AWS EC2 + ELB + ASG
No fancy container orchestration framework. Two ASGs per application for seamless canary + blue/green deploys. Started with Packer to build immutable AMIs, ended up using cloud-init to download a single binary from S3 at boot time.
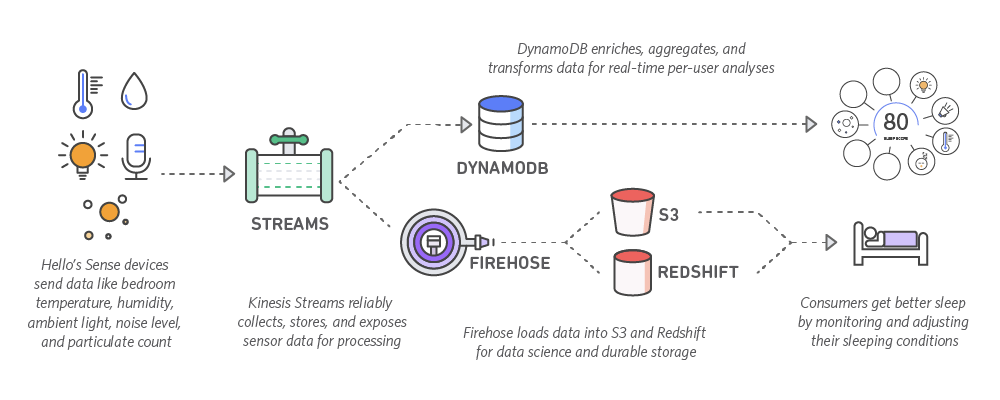
AWS Kinesis
PubSub for device <-> server data processing. Durable, auditable, replayable. Cost effective. 1/10 producer to consumers ratio. Ran into a few hard limits we had to work around.
Postges RDS + DynamoDB + Redshift
Started storing all time series data in Postgres. Daily tables. ~1 month of hot data available at all time with low latency. Dropping tables to reclaim memory/disk space. Multi AZ. Daily snapshots + exports to S3. Good performance. A little too manual for operations.
Moved to DynamoDB: one engineer wrote a simple sharding library for writes and reads over multiple partitions. Seamless migration. Great performance. Store all data for all time. Adjust throughput based on warm/cold data. Would have used AWS Aurora had it been available at the time.
All data available in redshift within minutes thanks to Kinesis Firehose S3/Redshift integration. Easy. Worked flawlessly.
Mini-Monoliths
Started with a mono-repo. Broke it up into 4 main applications when we understood what the business needed. A few shared libraries. Decoupled deployment cycles. Reliable. Predictable. Low amount of code duplication. Could have been better with regard to code coupling.
Long Polling
Long polling using Aleph for low latency Phone -> server -> device communications – in addition to BLE for Phone -> device. Easy to load balance, simpler for firmware. No WebSocket libraries available for our embedded stack. We attempted to move to WS at some point but the reliability wasn’t there.
Server driven back pressure
On every response sent to device, specify how long the device should buffer data before contacting server again. Helped reduce pressure when downstream dependencies (DynamoDB, Postgres) were having issues. Added intelligent scheduling based on time of day, device uptime, alarms, etc. Life saver. Ended up being a giant PID controller.
Feature flags
Instrumental to our high confidence deployment and release process. Requires good hygiene to avoid cluttering the code base too much.
Continuous Delivery for firmware builds
Fully automated deployments from Github PR merge to canary devices in less than 5 minutes. Built on top a rock solid OTA update process. No user interaction required. Safe, fast, automated.
Outsourcing
Hosted Graphite for metrics. Papertail for logs. PagerDuty, Travis CI, Searchify.
What worked okay
REST-ish HTTP/JSON API
For mobile <-> server communications. Grew organically, poor naming and inconsistent format for dates, timestamps and other potentially ambiguous fields. Mixed use of path and query parameters with no solid thought given. REST-ish, sometimes to its detriment. Suffered the most from our rapid release cycle.
OAuth2 scopes per endpoint
Started with simple uses cases, ended-up being only an somewhat poor fit for what we wanted. We needed real ACLs.
DB schema design
A few mistakes made early on for the sake of future optimizations ended up being costly in maintenance and performance. Ex: Storing pairing_id for all time series data required extra table lookups when data split between Postgres and DynamoDB.
Client Polling for phone <-> server communications
Implementing a web socket endpoint would have solved many race conditions and simplified client logic.
Non deterministic algorithm output.
Inherent to the nature of the problem we were solving, but could have done a better job earlier on. Latest implementation (RNNs) was deterministic and simpler to reason about.
Using feature flags for A/B testing
Don’t do it. Not a great fit. It worked, but too brittle.
Factory provisioning
This one is bittersweet. We went the extra mile with security for flashing Firmware at the factory but didn’t have the man power nor all the tooling required to make this seamless. End up being very secure but very manual.
What we probably should have done differently
Linux instead of FreeRTOS
Given our team size, the scope of what we wanted to achieve and our very aggressive timeline, in retrospect, building on top of a more powerful and more expensive platform would still have netted us a lot more in terms of velocity and simplicity. No wheels to reinvent, battle-tested filesystem implementation, standard tooling and most importantly a more accessible codebase for all team member to contribute/review.
Dependency injection
A mix of manual and library based (Dagger 1) dependency injection was cumbersome and complicated to maintain. Made the code harder to reason about. Trading compile time for runtime checks to avoid writing long constructors was not worth it.
Off-the-shelf SSL certificates
Caught in the required SHA1/SHA2 transition, limited support from the 3rd party MCU/SDK we were using. We should have issued our own certs from the beginning.
Conclusion
I have glossed over many other technology choices we also made (Objective-C vs Swift), RxJava on Android, ANT vs BLE, etc.
They were made with the same goal in mind: to build performant, reliable software with a small team. There is no silver bullet in software development, just a few principles that can help along the way. For us it was chosing technologies that aligned with our engineering values.